
-
2019 Ecommerce Oddities
-
Credit Card Testing
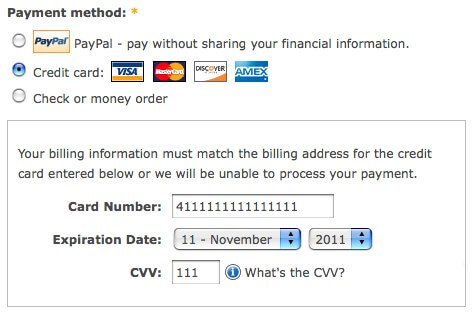
-
Google Chrome Logging Customers Out
Zen Cart isn’t the only platform having these issues with Chrome. The issue isn’t with your Zen Cart, but rather with Chrome. Here is what happens when Chrome users, especially mobile users, are trying to shop on your Zen Cart but keep getting logged out. Symptom: User adds something to cart, tries to login, checkout…
-
Mobile-First Indexing
So logging in to webmaster tools following an email from Google about Mobile-First Indexing on one of our sites, we found the following documentation. Mobile-first indexing enabled for https://mysite.com/ May 17, 2018 To owner of https://mysite.com/, This means that you may see more traffic in your logs from Googlebot Smartphone. You may also see that…
-
Google Dictates Blanket SSL for All